 Too Long; Didn't Read
Too Long; Didn't ReadHallucinations Are Not Quirks. They Are Pipeline Failures
In production systems, non-determinism is a bug.
We tolerate “creative drift” in research labs and demo threads. We do not tolerate it in infrastructure.
An AI hallucination is not a personality trait of a model. It is not “the spark of AGI” leaking through. From a systems perspective, it is a failure in the inference pipeline, no different in spirit from reading uninitialized memory, racing a distributed lock, or returning stale cache entries. The structure looks valid. The headers parse. The payload is garbage.

In 2026, this problem has moved well beyond chat bubbles. We are deploying agentic workflows: LLMs that chain tools, write executable code, modify cloud resources, and call internal APIs. A hallucination in this context is not embarrassing. It is a catastrophic failure mode. One fabricated hostname, one imaginary API field, or one confident but false compliance claim can cascade across services like a broadcast storm.
Large language models are probabilistic text engines wrapped in deterministic shells. Treating hallucinations as “prompting issues” is like blaming user input for a buffer overflow. The fix lives in the architecture, not in the vibes of your prompt.
This is a field guide to the containment layers required to run these systems safely.
The Taxonomy of Error: Why Hallucinations Actually Happen
If you have ever debugged a distributed system, you know that “it just broke” is never the answer. Hallucinations emerge where specific system constraints collide.
1. Data Gaps (The Knowledge Boundary)
LLMs interpolate; they do not retrieve.
When a prompt crosses outside the model’s training distribution or the provided context window, the model fills the gap with statistically plausible tokens. This is equivalent to dereferencing a null pointer. The model does not have an internal 404 Not Found state unless you build one.
2. Sampling Parameters (Entropy as a Risk Multiplier)
Temperature, Top-P, and Top-K are not creativity knobs. They are entropy injectors.
Increasing entropy raises token diversity, which mathematically increases the probability of unsupported claims. In infrastructure terms, this is like loosening consistency guarantees under load “just to see what happens.” High entropy belongs in experiments, not production paths.
3. Context Window Saturation (The Sliding Window Problem)
Modern models advertise massive context windows, but reasoning density is not uniform.
As prompts grow, early facts decay and the “lost in the middle” effect takes over. The model optimizes for local coherence instead of global correctness. Treat long prompts like long-running processes: they leak reliability over time.
The 2026 Tooling Stack: A Three-Layer Defense Model
You do not secure a network with a single firewall. You use layered defenses.
The same applies here:
I. Evaluation Frameworks (The Pre-Deployment Layer)
This is CI/CD for LLMs.
If a hallucination reaches a user, your evaluation layer failed.
You do not test LLMs by chatting with them. You test them against deterministic benchmarks.
Key Tools
- DeepEval
A unit-testing framework that uses LLM-as-a-judge to score faithfulness and relevance. - Ragas
The standard for RAG pipelines, measuring context relevance, faithfulness, and answer relevance. - Promptfoo
A CLI-first tool for running test cases across dozens of models to find where your logic breaks.
Sysadmin Spec: CI/CD Integration
Stop manually checking outputs. A minimal pipeline looks like this:
# Hypothetical promptfoo-action.yaml
steps:
- name: Run Hallucination Regression Tests
run: npx promptfoo eval
env:
THRESHOLD: 0.95
- name: Check Token Usage & Latency
run: python check_metrics.py
Pro-Tip: Lock your evaluation datasets. If your gold set drifts, your metrics become noise. Version eval data like code.
II. Real-Time Guardrails (The Runtime Layer)
Runtime defense is about containment, not trust.
Assume the model will lie. Build a sandbox it cannot escape.
The Tools
- NVIDIA NeMo Guardrails: Uses “Colang” to define hard boundaries. It can force the model to stay on topic or check the output against a secondary “fact-checking” model before the first token reaches the user.
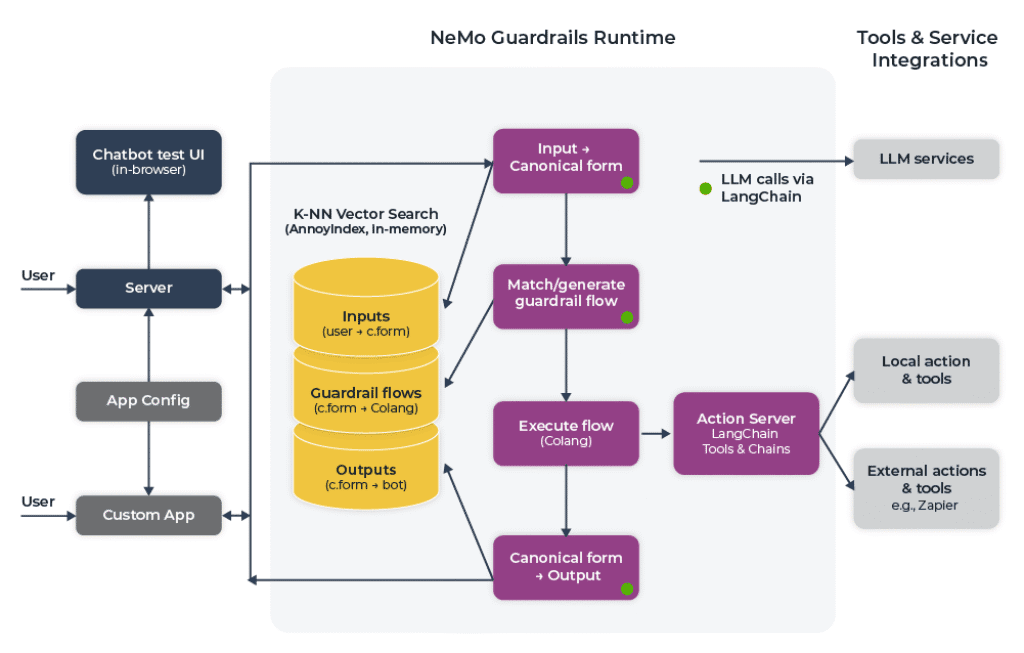
- Guardrails AI: Excellent for Schema Enforcement. If you need your AI to output JSON for an API call, Guardrails AI validates the Pydantic schema in real-time. If the AI fabricates a field, the guardrail catches the
ValidationErrorand triggers a re-ask or a failure.
The “Latency Tax” Analysis
Every guardrail is a middleware. In the Sysadmin world, middleware means latency.
- Token-level interception: Checking every token as it’s generated adds significant overhead to your Time to First Token (TTFT).
- Full-response validation: Waiting for the whole string to finish before validating kills the user experience.
2026 Strategy: Use “Small Language Models” (SLMs) like Phind-7B or Llama-3-8B as your guardrail engines. They are low-latency and “cheap” enough to run as sidecars to your main inference calls.
Pro-Tip: Fail Closed. If a guardrail detects a hallucination, do not let the model “try again” indefinitely. Return a standard error code or a null response. Silence is always safer than a confident lie in a production system.
III. Observability & Tracing (The Post-mortem Layer)
When a hallucination escapes into the wild and it will, you need a stack-trace.
Key Tools
- Arize Phoenix: An open-source observability library that provides “Traces” for your LLM calls. It shows you exactly what was retrieved from your database, what the prompt looked like, and where the model started to hallucinate.
- LangSmith: If you are using LangChain, this is your debugger. It allows you to “replay” a failed execution with different parameters to find the root cause.
Root Cause Analysis (RCA) for AI
In 2026, an RCA for a hallucination should answer:
- Was the retrieved context relevant? (Vector DB Failure)
- Did the model ignore the context? (Instruction Following Failure)
- Did the temperature spike entropy? (Config Failure)
Without tracing, you are just “poking the box” with new prompts and hoping for the best. That is not engineering; that is superstition.
The Senior Engineer’s Corner: Architectural Deep-Dives
1. Self-Correction Loops (Idempotency for Reasoning)
A self-correction loop is a pattern where the model critiques its own work.
- Step A: Generate the output.
- Step B: Critique using a colder model
- Step C: Rewrite if violations exist.
This is essentially Defensive Programming. You are building a retry-logic into your reasoning engine.
2. RAG Hygiene (The Root of All Evil)
Most RAG hallucinations are retrieval failures. If your Vector Database returns “noise,” the model will treat that noise as “signal” and weave a narrative around it.
The 2026 Checklist for RAG Stability:
- Semantic Chunking: Don’t just split text every 500 characters. Use semantic boundaries so the model gets complete thoughts.
- Hybrid Search: Combine Vector search (distance-based) with BM25 (keyword-based). This prevents the model from hallucinating a “related” topic when it should have looked for a specific Serial Number or Error Code.
- Re-ranking: Use a Cross-Encoder (like BGE-Reranker) to score the top 10 results from your database.
Level 0: Practical Advice for Individuals
If you aren’t building an enterprise agent but just want your personal instance of GPT or Claude to stop lying to you, follow the “Sysadmin Basics”:
- Temperature 0.0: For anything factual, turn the “creativity” off.
- The “Check Your Work” Clause: Always end your prompt with: “If the answer is not contained in the provided documents, state that you do not know. Do not use outside knowledge.”
- Chain of Verification (CoVe): Ask the model to first list the facts it will use, then verify those facts, then write the final answer.
- Audit Logs: Use a tool like ChatHub or typingmind to export and save your prompts/responses. If it lies once, it will lie again. Find the pattern.
Conclusion: The Sysadmin’s Verdict
There is one inconvenient truth about preventing AI hallucinations: You do not prevent them with better prompting.
You prevent them with Verification.

Large Language Models are probabilistic systems. They are designed to predict the next token, not to verify the truth. That is not a moral failing; it’s a mathematical property. Your job as a Systems Administrator or Engineer is not to demand “truth” from a stochastic engine, it is to build a deterministic framework around it.
- Validate the inputs.
- Constrain the outputs.
- Observe the failures.
Treat LLMs like untrusted, third-party binaries running on your kernel. Wrap them in permissions, monitor their resource usage, and keep them in a sandbox. That mindset is the difference between an AI demo and production-grade infrastructure.
The truth is found in the logs, not the prompt.

